O que são Logs de Crawlers?
Logs de Crawlers rastreia como os crawlers (bots) de modelos de IA acessam e indexam seu site. Assim como os crawlers de mecanismos de busca (Googlebot, Bingbot), modelos de IA têm seus próprios crawlers que visitam páginas web para coletar informações. Entender esse comportamento de rastreamento é essencial para otimizar a visibilidade do seu site em IA. Se os crawlers de IA não estão visitando suas páginas principais, os modelos de IA podem não ter informações atualizadas sobre sua marca, o que impacta diretamente sua visibilidade em respostas geradas por IA.Como funciona
O First Answer integra-se com os logs do servidor do seu site ou analytics para detectar visitas de crawlers de IA conhecidos. Ele então categoriza e visualiza essa atividade para que você possa entender:- Com que frequência cada modelo de IA rastreia seu site
- Quais páginas eles visitam com mais frequência
- Como os padrões de rastreamento mudam ao longo do tempo
Seções do painel
Rastreamentos ao Longo do Tempo
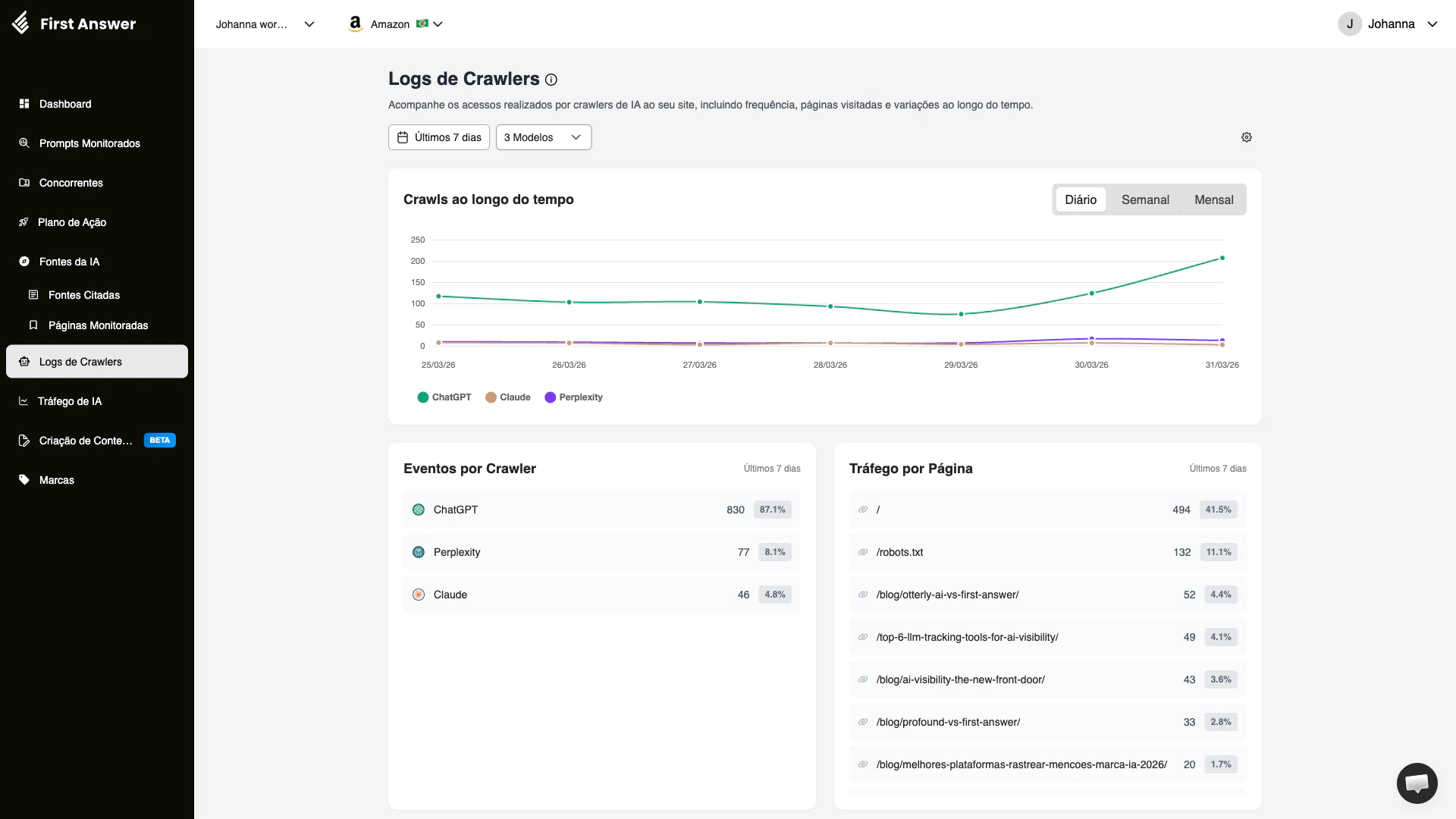
Um gráfico de série temporal mostrando o total de eventos de rastreamento por dia, semana ou mês. Você pode alternar entre visualizações Diária, Semanal e Mensal. Cada modelo de IA é representado por uma cor diferente, facilitando ver quais modelos estão rastreando seu site mais ativamente.Eventos por Crawler
Uma divisão do total de eventos de rastreamento por modelo de IA:- Nome do crawler: O crawler do modelo de IA (ex: ChatGPT, Perplexity, Claude)
- Contagem de eventos: Total de eventos de rastreamento no período selecionado
- Porcentagem: A participação do crawler no total de atividade de rastreamento
O crawler do ChatGPT (GPTBot) é tipicamente o mais ativo, mas os padrões de rastreamento variam por site. Se um crawler específico não está visitando seu site, verifique seu
robots.txt para garantir que você não está bloqueando-o.Tráfego por Página
Mostra quais páginas do seu site recebem mais tráfego de rastreamento dos bots de IA:- URL da página: A página específica sendo rastreada
- Contagem de visitas: Quantas vezes a página foi rastreada
- Porcentagem: A participação da página no total de visitas de rastreamento
Filtros
- Período: Padrão são os últimos 7 dias, mas você pode ajustar para ver tendências mais longas
- Modelos: Filtre por crawlers de modelos de IA específicos
Conceitos-chave
Por que a frequência de rastreamento importa
Modelos de IA só podem incluir informações de páginas que rastrearam. Se um crawler não visitou sua página recentemente, o modelo de IA pode não saber sobre:- Novos produtos ou serviços que você lançou
- Preços ou funcionalidades atualizados
- Posts de blog ou conteúdos recentes
robots.txt e crawlers de IA
Seu arquivorobots.txt controla quais crawlers podem acessar seu site. Alguns sites bloqueiam crawlers de IA sem querer. Os principais user agents de crawlers de IA incluem:
| Modelo de IA | User Agent |
|---|---|
| ChatGPT | GPTBot |
| Google Gemini | Google-Extended |
| Perplexity | PerplexityBot |
| Claude | ClaudeBot |
| Bing Copilot | Bingbot |
Priorização de páginas
Crawlers de IA não visitam todas as páginas igualmente. Eles priorizam páginas com base em:- Autoridade: Páginas com mais links de entrada são rastreadas com mais frequência
- Atualidade: Páginas recentemente atualizadas podem ser re-rastreadas mais cedo
- Inclusão no sitemap: Páginas listadas no seu sitemap são mais fáceis para os crawlers descobrirem
- Linkagem interna: Páginas bem linkadas são rastreadas com mais frequência
Como usar Logs de Crawlers
Verifique se crawlers de IA podem acessar seu site
Confirme que seu
robots.txt não bloqueia user agents de crawlers de IA. Se você vir zero eventos de rastreamento para um modelo específico, provavelmente é esse o problema.Identifique suas páginas mais rastreadas
Revise a seção Tráfego por Página. Suas páginas mais importantes (páginas de produto, landing pages principais) devem estar entre as mais frequentemente rastreadas.
Monitore tendências de rastreamento
Use o gráfico Rastreamentos ao Longo do Tempo para identificar mudanças no comportamento de rastreamento. Uma queda repentina pode indicar um problema técnico (bloqueio no robots.txt, erros de servidor ou site fora do ar).